今天中午的时候没事,随手打开掘金app打算看看最近有什么好文章。看到热门推荐下有一篇文章名为 qanswer:冲顶大会等游戏答题神器(Golang) 号称《冲顶大会》,《百万英雄》等答题游戏的答题神器,让人顺利吃鸡!
因为我最近也一直在关注西瓜视频里的“百万英雄”这个“全民直播答题吃瓜”的活动,但无奈自己的知识储备量太少,最高的一次答到第9题就被kill了。看到这篇文章顿时来了兴趣,准备好好研究一番。
该项目的github地址为 silenceper/qanswer 。在 README.md 中也记录了如何来部署运行,下面把我的部署流程简单的记录如下。
qanswer部署
我使用的设备是 MacBook Pro,手机是 红米Note4x 高通版,分辨率为1920x1080。
对于其他平台如 Win或Linux,我也会顺带提一下。
安装go环境
配置golang运行环境,可以直接参考我之前写的博客文章来安装:Golang运行环境配置
安卓设备
连接安卓设备时需要安装一个驱动类工具adb。adb全称为 Android Debug Bridge ,即Android调试桥。Android 调试桥 (adb) 是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试应用,并提供对 Unix shell(可用来在模拟器或连接的设备上运行各种命令)的访问。
Mac系统安装adb
通过 homebrew 来安装,执行如下命令:
1 | $ brew cask install android-platform-tools |
当看到提示 android-platform-tools was successfully installed! 信息,说明安装成功。
命令 adb devices 可以用来查看当前连接的安卓设备:
1 | $ adb devices |
可见当前并没有连接的设备。
Ubuntu安装adb
使用如下的命令来安装:
1 | sudo add-apt-repository ppa:nilarimogard/webupd8 |
Win安装adb
直接下载解压后就可使用 Download the ADB ZIP file for Windows
ios设备
对于ios设备,需要安装WDA。
具体的安装方法可参考项目中给出的文章 iOS 真机如何安装 WebDriverAgent
开启小米手机 MIUI9 USB调试模式
为了能够调试手机,需要打开小米手机或其他安卓手机的USB调试模式。
小米手机 MIUI9系统的开启方法:
- 打开 “设置” – “我的设备” – “全部参数” 页面
- 然后连续三次以上点击“MIUI版本”一栏,会出现 开发者模式已打开的提示信息
- 返回设置主界面,进入“更多设置”,在无障碍选项下面出现了“开发者选项”,点击进入
- 在开发者选项中就可以找到“USB调试”,启用即可
通过数据线连接手机,再次执行上面命令:
1 | $ adb devices |
可以看到发现了我的安卓手机,并连接上了。
文字识别
对于文字图像识别,项目中实现了两种方式:百度ocr 和 tesseract。这里我采用百度ocr来实现。
从百度的文字识别接口网站 百度文字识别 中,登录百度云管理平台后,在左侧选择“产品服务”–“人工智能”–“文字识别” 一项,选择 “创建应用” 就可以获得需要的api key 和secret key。
百度的文字识别接口有 500次/天 的免费使用权限,一般也够用了。
运行
将项目克隆到 gopath 目录下 git clone https://github.com/silenceper/qanswer.git,如我这里是 /Go/xgo_workspace/src 目录下,然后添加项目引用:
1 | $ go get github.com/silenceper/qanswer |
执行编译:
1 | $ cd qanswer/cmd |
然后会在 qanswer 目录下生成一个名为 qanswer 的执行文件。
执行该程序:
1 | $ ./qanswer |
结果输出:
1 | 配置文件:./config.yml |
设置配置文件
程序运行用到的配置文件是在当前目录下的 config.yml 文件。
配置参数说明如下:
1 | # 是否开始调试模式 |
成功的关键
在上面的配置文件中,关键的一点就是配置文件中设置的对于不同手机类型及不同分辨率的坐标设定了。
你需要根据自己手机对直播问答页面进行截图后获取的坐标点及像素长度来设定。
1 | # 截取题目的位置 |
对直播答题界面截屏,然后通过Mac系统自带的图片预览可以得到该界面中题目左上角顶点的x坐标位置和y坐标位置以及题目区域的宽度和高度。
同理能够获得答案部分的值。
这里要提一下的是,这里的坐标是向右为x轴正方向,向下为y轴正方向。所以值均为正数。
经过测量,我的手机的配置信息如下:
1 | # 百万英雄 红米Note4x 高通版 1920x1080 |
另外,baidu_api_key 和 baidu_secret_key 设置成在百度文本识别中创建应用的对应值。如果使用的是 tesseract 这两项则不用管。
执行效果
1 | 配置文件:./config.yml |
另外附上一些执行过程截图:
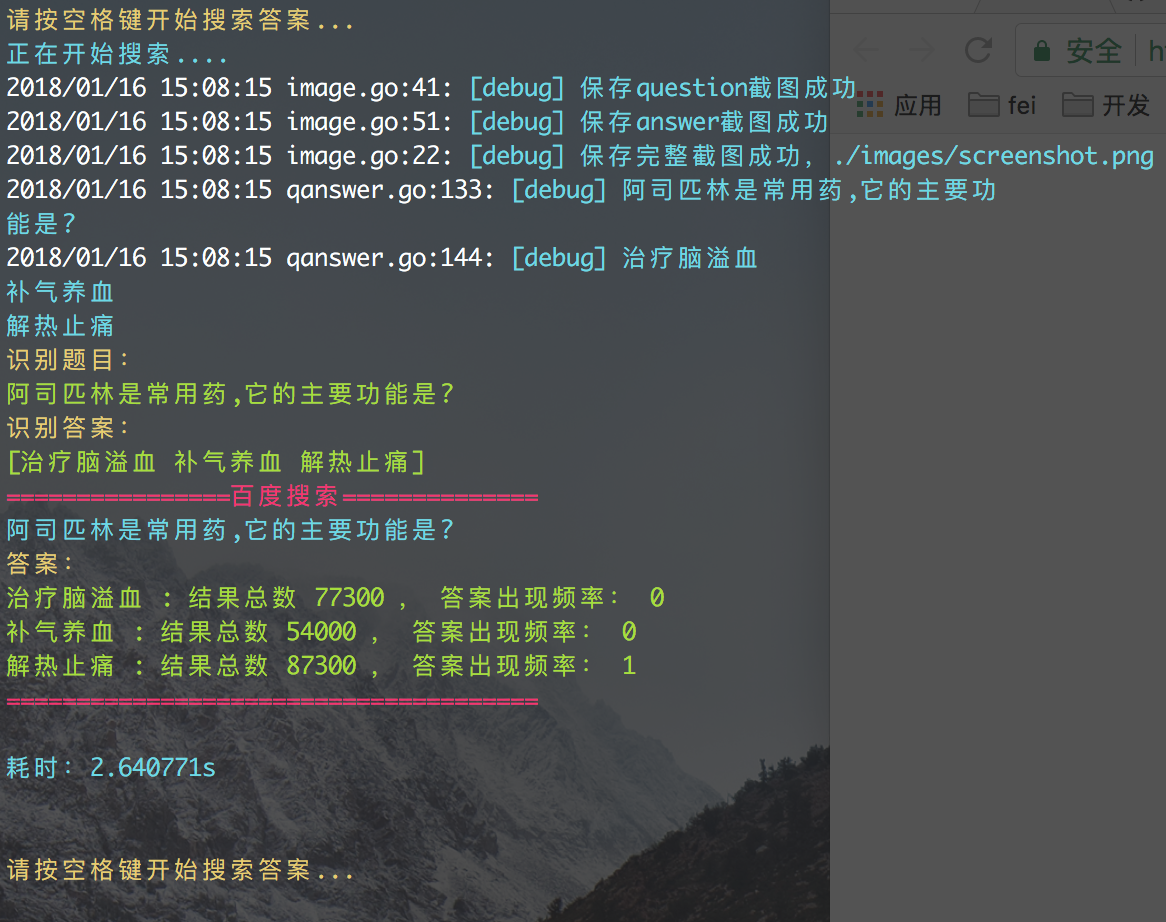
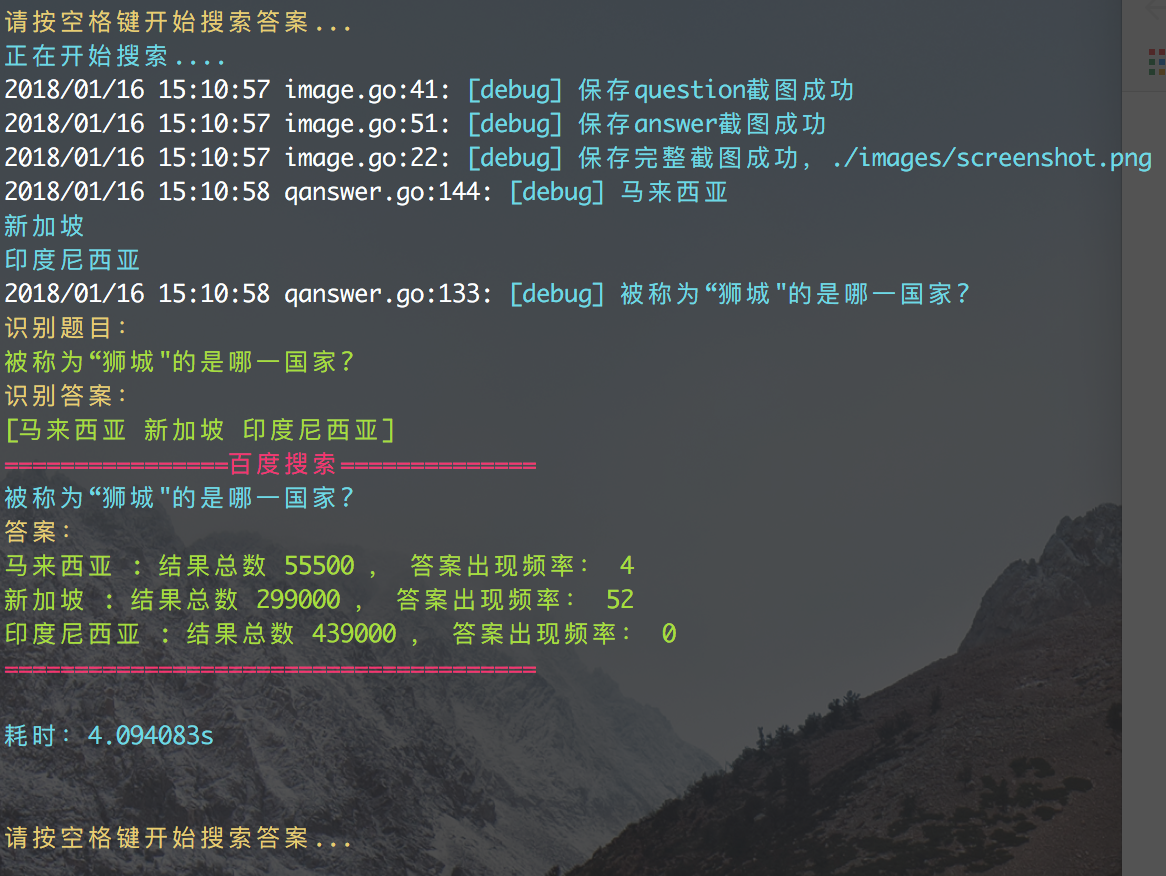
出现的问题
在实际的测试中,我也发现了该项目的一些问题。
判断逻辑的可行性
目前该项目中使用的搜索引擎是百度。
而程序当前对问题答案获取的后台逻辑是:通过将问题和三个不同的答案拼接输出到搜索引擎中进行搜索查询,如使用百度,在搜索结果页面中会输出:“百度为您找到相关结果约487,000个” 类似这样的一段话。而答案的判断逻辑就是看三种答案对应的搜索结果的数据总条数来预测该答案可能为正确的答案。
但这样的方法并不一定能保证完全的正确,如下面的一个问题:
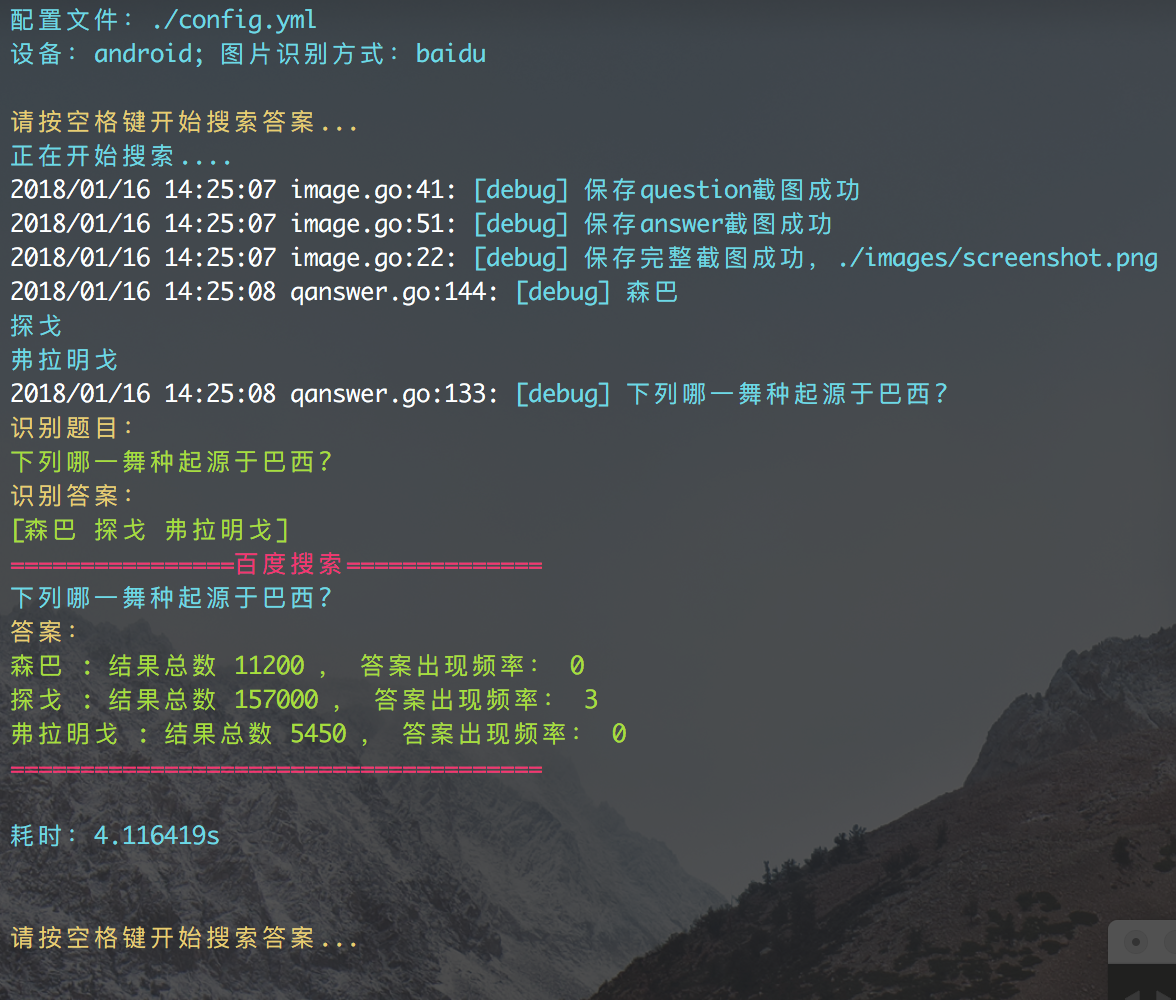
如果按照推荐的答案,要选 “探戈” 。而这道题的正确答案应该是 “森巴” 。
后来,我又对其他常用的搜索引擎做了对比。如我对比了 Baidu 、Bing国内版 、 Bing国际版 和 Google(需FQ) ,结果发现这四种搜索结果的正确率为:
Google > Bing国际版 > Bing国内版 > Baidu
但是后来我增加了问题的测试数量,发现Google对于答案的判断正确率也比较低。
例如其中的一个问题:
哪一种反应属于化学反应?
食物腐烂
冰化水
玻璃碎成块
通过百度测试,对于三个答案的搜索结果数量为:
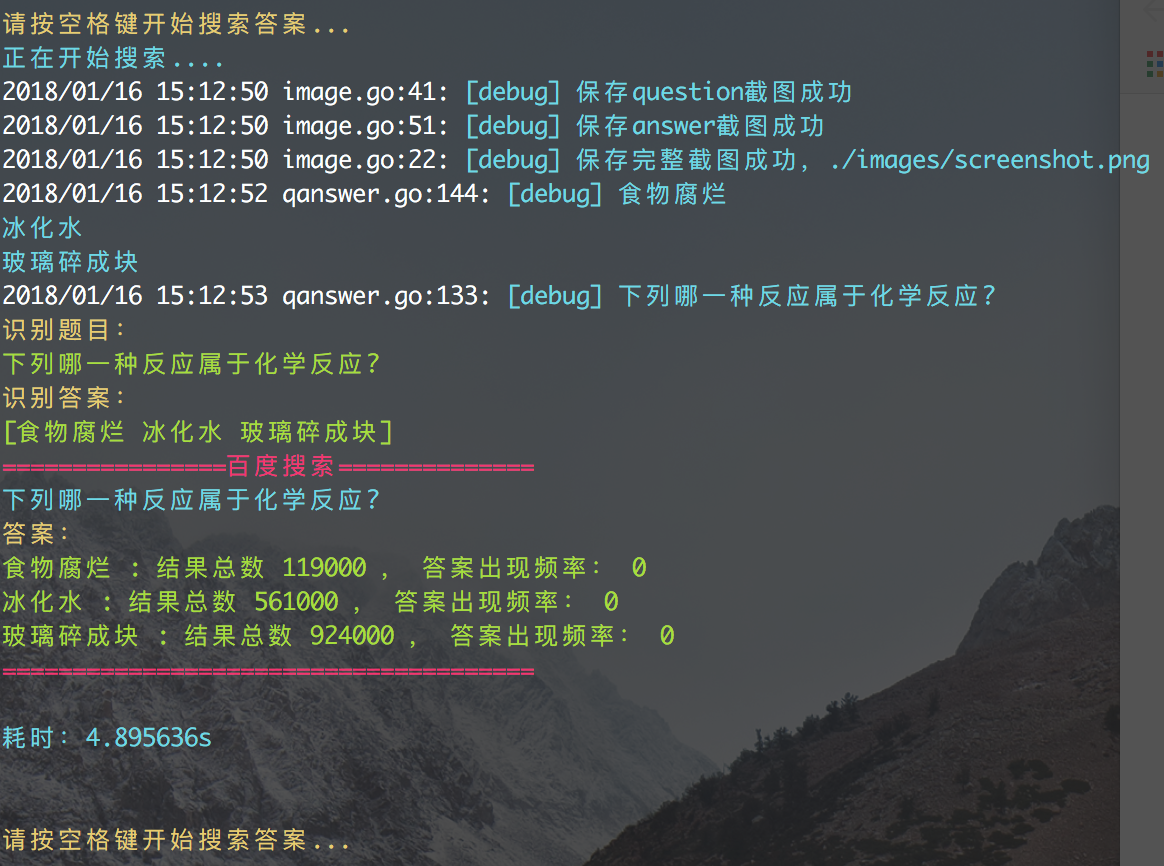
可见,按照搜索数量结果来看的话,要选 “玻璃碎成块” ,但正确的答案应该是 “食物腐烂”。
后来我又使用 google 进行了测试:
食物腐烂 98400
冰化水 483000
玻璃碎成块 116000
可见在Google下这种方式得到的答案也不正确。
所以,我觉得这种判断逻辑只能给出70%的正确率,在答题过程中也仅仅作为参考答案,而不能一味的相信。
否定句
如果遇到标题是否定句式的情况,通过上面这种搜索的形式就无法找到正确的答案了,一般搜索出来的也是“肯定句式”下的答案。
比如下面这个问题:
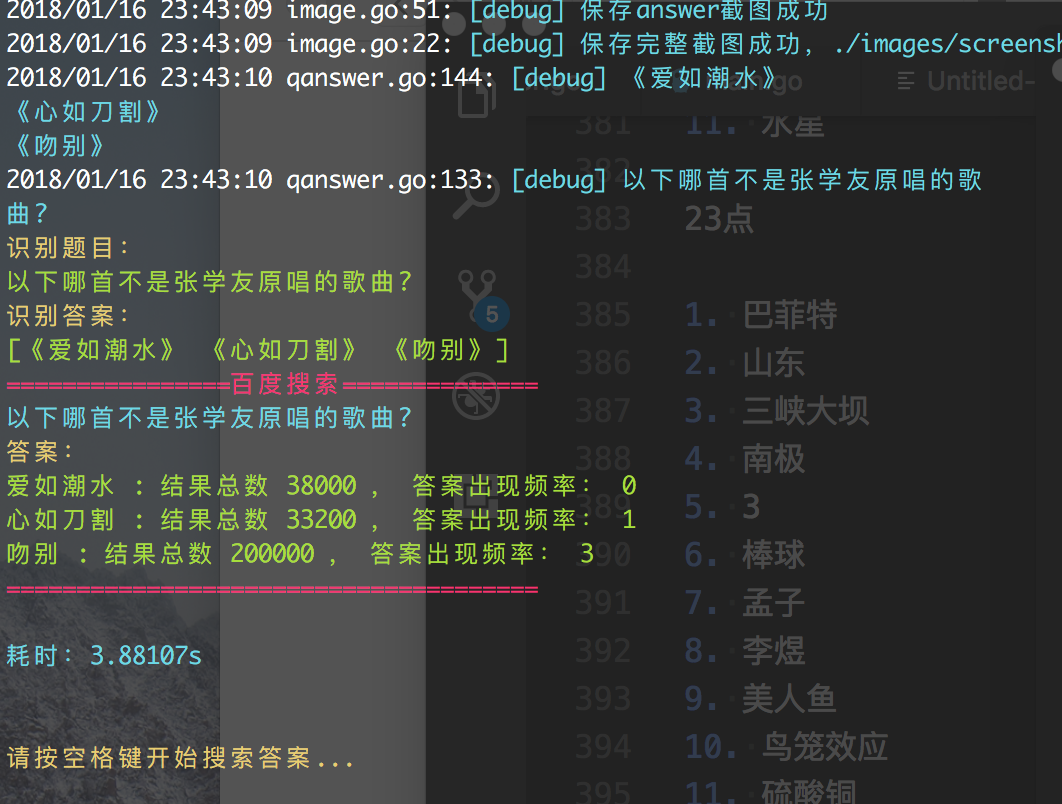
正确的答案应该是 爱如潮水。
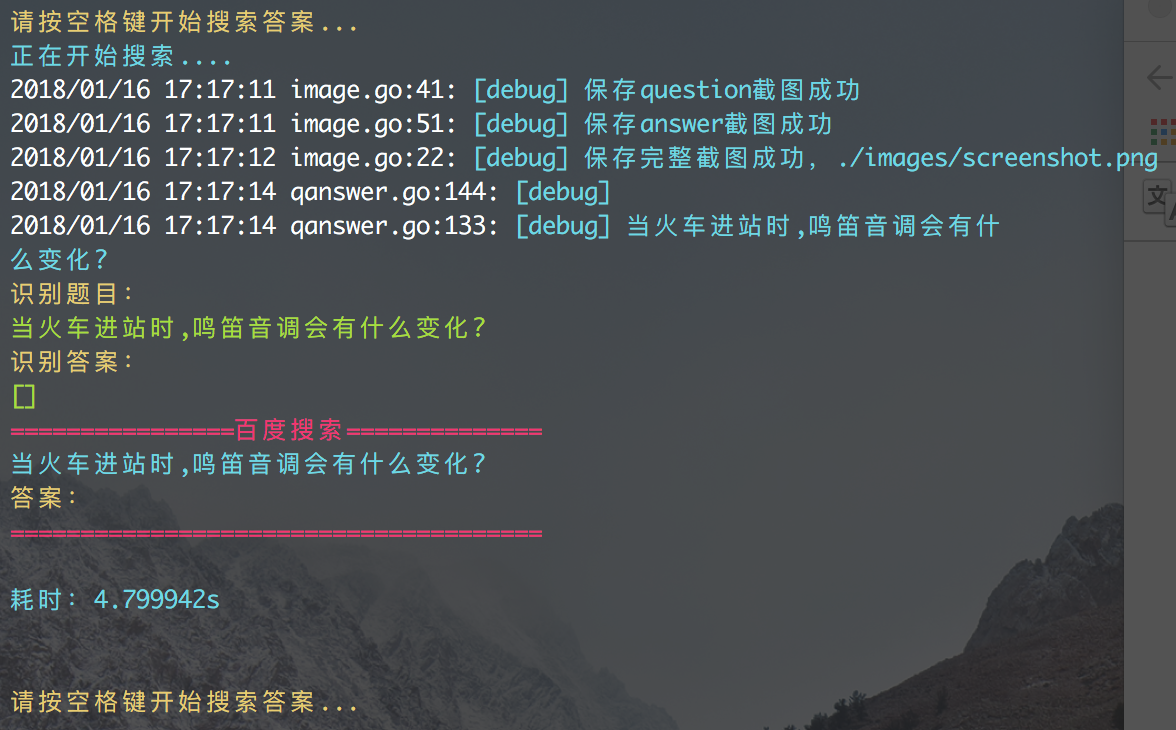
文字识别出错
还有一种情况就是图像文字没有识别出来的情况,最后也就不能给出相应的答案了。
其他方法实现
个人认为类似这种问答类的题目,可行的方式比如对问题进行分词处理,然后对关键词去搜索匹配,通过词频来判断;或者弹出浏览器由用户自己去判断最终的答案,一般像搜索引擎的搜索结果页面,都会有标题和简短的内容,内容中的关键字会被标红显示,由用户自己去判断,准确性会更高一些,但这样耗费的时间也会特别长。应该还有其他的方法吧。
目前我也在用python来实现一种可能的方法,我会在后续的文章中详细说明,敬请期待吧!
最后再说一句。如果看到这篇文章后你也对这种“答题吃瓜”的直播问题活动产生了兴趣,可以使用我的邀请码来获得一张复活卡的机会,输入下面的邀请码即可。


